How to extract and index CVE data using OpenSearch

Here in this article we will see how we can download and extract CVE database JSON feed. Once we have the JSON data we will be using a python based script to extract individual CVE JSON document and index it in Opensearch search and analytic tool.
Test Environment
Fedora 35 server
Docker version 20.10.12
docker-compose version 1.29.2
What is CVE and CVE database
Common vulnerabilities exposure (CVE) is a database of publicly disclosed information security issues. Whenever there is a vulnerability identified within any product, software it is usually notified by the individual or vendor to the respective Product Owner or Organization through a secure communication channel. Usually the vulnerability once identified it won’t be published to CVE database unless their is either a fix available or some kind of mitigation plan or workaround available to address it. Once a vulnerability fix or mitigation plan or workaround is available it will be provided with an identification number called CVE number which is in the format of CVE– (eg CVE-2022-23305).
What is NVD
The National Vulnerability Database (NVD) provides CVSS Based Scores, fix information, and other important details often needed by information security teams that want to mitigate the vulnerability or assess its overall priority. This mitigation or workaround information is not available in the CVE database.
What is CVSS
Common Vulnerability Scoring System (aka CVSS Scores) provides a numerical (0-10) representation of the severity of an information security vulnerability. CVSSv3 looks at the privileges required to exploit a vulnerability, as well as the ability for an attacker to propagate across systems (“scope”) after exploiting a vulnerability. Once analysed, the scoring and severity are assigned as per the below table.
| CVSS Score | Qualitative Rating |
| 0.0 | None |
| 0.1 – 3.9 | Low |
| 4.0 – 6.9 | Medium |
| 7.0 – 8.9 | High |
| 9.0 – 10.0 | Critical |
Let’s get started.
If you are intereseted in watching the video. Here is the YouTube video on the same step by step procedure outlined below.
Procedure
Step1: Instantiate Opensearch using a docker-compose file
Here we are using a docker-compose.yml file to setup our Opensearch search and analytic tool. This cluster consist of a single node and also along with Opensearch we are instantiating opensearch-dashboards service which we can used as visualization tool for data in Opensearch. Please note the volume mount named ‘opensearch-data1’ for Opensearch data persistence.
File: docker-compose.yml
[admin@fedser32 opensearch-docker]$ cat docker-compose.yml
version: '3'
services:
opensearch-node1:
image: opensearchproject/opensearch:1.2.4
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node1
- discovery.seed_hosts=opensearch-node1
- cluster.initial_master_nodes=opensearch-node1
- bootstrap.memory_lock=true # along with the memlock settings below, disables swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # minimum and maximum Java heap size, recommend setting both to 50% of system RAM
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536 # maximum number of open files for the OpenSearch user, set to at least 65536 on modern systems
hard: 65536
volumes:
- $PWD/opensearch-data1:/usr/share/opensearch/data
ports:
- 9200:9200
- 9600:9600 # required for Performance Analyzer
networks:
- opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:1.2.0
container_name: opensearch-dashboards
ports:
- 5601:5601
expose:
- "5601"
environment:
OPENSEARCH_HOSTS: '["https://opensearch-node1:9200","https://opensearch-node2:9200"]' # must be a string with no spaces when specified as an environment variable
networks:
- opensearch-net
volumes:
opensearch-data1:
networks:
opensearch-net:
Instantiate the Opensearch and Dashboard service.
docker-compose up -d
The Opensearch dashboard can now be accessed using the below URL.
URL - http://fedser32.stack.com:5601/ (Please change the FQDN to your server name or localhost)
Now that we have our Opensearch service up and running. Let’s proceed to look the python script details to Download, Extract and Index the CVE JSON data.
Step2: Import modules and initialize the environment variables
Here we are importing modules requests, gzip and json to download, extract and working with the json data. Also we have setup some environment variables related to Opensearch service url and its default authentication credentials. As i am going to use Opensearch without SSL setup i am setting the sslcheck environment variable to ‘False’. For indexing the data in Opensearch we can provide a name for the index, in our case we are setting it using ‘indexname’ environment variable.
import json
import gzip
import requests
# CVE feed
cvefeed = "https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-2022.json.gz"
# Opensearch environment variables
baseurl = "https://fedser32.stack.com:9200"
username = "admin"
password = "admin"
auth = (username, password)
sslcheck = False
# Index variables
indexname = "cveindex"
Step3: Download and Extract the CVE database json feed
The CVE JSON data feeds are available in JSON and XML format at the following locaiton – https://nvd.nist.gov/vuln/data-feeds. We will be working the JSON data feed in this article. The JSON data feeds are availble for each year since 2002 which are updated once daily and CVE-Recent and CVE-Modified json feeds are updated every 2 hours. We will be working with CVE-2022 json feed which is for this year.
Here is the below function which will help to download and extract the CVE json data and convert it into a dictionary to work in python.
def extractCVEData(cvefeed):
gzfile = requests.get(cvefeed).content
jsondata = gzip.decompress(gzfile)
data = json.loads(jsondata)
return data
Step4: Count the CVE items
Once we have prepared the dictionary of the CVE items above we can pass that data to below function to identify the number of CVE items present in the CVE json feed which we downloaded.
def countCVE(cvedata):
data = json.loads(cvedata)
count = len(data['CVE_Items'])
return count
Step5: Create an Index
Now, let’s create our index named ‘cveindex’ by calling the below function. This will create our index in Opensearch tool.
def createIndex(baseurl, auth, sshcheck, indexname):
print("Create Index....................................")
createIndexRes = requests.put(baseurl+"/"+ indexname, auth=auth, verify=sslcheck)
print(createIndexRes.status_code)
Step6: Index CVE JSON items
This function will help us to index each document in the JSON feed. We are going to iterate using the cvecount and retrieve every single CVE item pass it to this function for indexing purpose.
def addData(baseurl, auth, sslcheck, indexname, document, docID):
print("Add Data........................................")
headers = {'Content-type': 'application/json'}
#data = {"Description": "To be or not to be, that is the question."}
data = document
addDataRes = requests.put(baseurl+"/"+ indexname + "/_doc/"+ str(docID), json=data, auth=auth, verify=sslcheck, headers=headers)
print(addDataRes.status_code)
Here is my complete python script for the same.
File: extractIndexCveData.py
import json
import gzip
import requests
# CVE feed
cvefeed = "https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-2022.json.gz"
# Opensearch environment variables
baseurl = "https://fedser32.stack.com:9200"
username = "admin"
password = "admin"
auth = (username, password)
sslcheck = False
# Index variables
indexname = "cveindex"
def extractCVEData(cvefeed):
gzfile = requests.get(cvefeed).content
jsondata = gzip.decompress(gzfile)
data = json.loads(jsondata)
return data
def countCVE(cvedata):
data = json.loads(cvedata)
count = len(data['CVE_Items'])
return count
def createIndex(baseurl, auth, sshcheck, indexname):
print("Create Index....................................")
createIndexRes = requests.put(baseurl+"/"+ indexname, auth=auth, verify=sslcheck)
print(createIndexRes.status_code)
def addData(baseurl, auth, sslcheck, indexname, document, docID):
print("Add Data........................................")
headers = {'Content-type': 'application/json'}
#data = {"Description": "To be or not to be, that is the question."}
data = document
addDataRes = requests.put(baseurl+"/"+ indexname + "/_doc/"+ str(docID), json=data, auth=auth, verify=sslcheck, headers=headers)
print(addDataRes.status_code)
cvedata = extractCVEData(cvefeed)
#print(cvedata)
cvecount = len(cvedata['CVE_Items'])
print(cvecount)
createIndex(baseurl, auth, sslcheck, indexname)
for item in range(cvecount):
cveitem = cvedata['CVE_Items'][item]
print(cveitem)
print(item)
addData(baseurl, auth, sslcheck, indexname, cveitem, item)
Execute the script to download, extract and index the data.
python extractIndexCveData.py
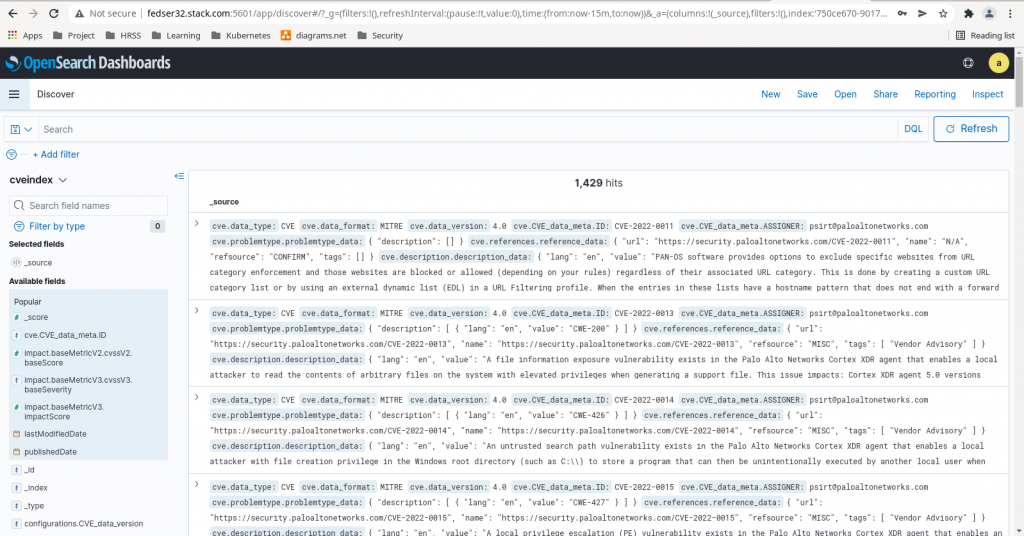
So, we have now downloaded, extracted and indexed our JSON data which should be available in our Opensearch index named ‘cveindex’ as shown in below screenshot.
Hope you enjoyed reading this article. Thank you..
Leave a Reply
You must be logged in to post a comment.