How to index json dataset in Elasticsearch

Here in this article we will see how we can index a json dataset consisting of documents in elasticsearch. We will be setting up elasticsearch cluster and use a python script to extract the documents from json dataset and send it to elasticsearch for indexing.
Test Environment
Fedora workstation 37
Docker
Docker Compose
If you are intereseted in watching the video. Here is the YouTube video on the same step by step procedure outlined below.
Procedure
Step1: Download json datasets
For this article i am downloading a sample dataset available at the following github respository – awesome-json-datasets.
wget http://api.nobelprize.org/v1/prize.json
Step2: Install jq
As a part of second step we are installing jq tool. jq is a command line json processor which can be used to slice, filter, map and transform with the json formatted data. We can use this tool to inspect json data in a readable format.
sudo dnf install jq
Step3: Inspect json data
In this step we will using jq processor to inspect our prizes.json dataset and verify what kind of documents are present in this dataset and what are different types of data present in each of these fields.
File: prizes.json
[admin@fedser elastic-kibana]$ cat prize.json | jq
{
"prizes": [
{
"year": "2022",
"category": "chemistry",
"laureates": [
{
"id": "1015",
"firstname": "Carolyn",
"surname": "Bertozzi",
"motivation": "\"for the development of click chemistry and bioorthogonal chemistry\"",
"share": "3"
},
{
"id": "1016",
"firstname": "Morten",
"surname": "Meldal",
"motivation": "\"for the development of click chemistry and bioorthogonal chemistry\"",
"share": "3"
},
{
"id": "743",
"firstname": "Barry",
"surname": "Sharpless",
"motivation": "\"for the development of click chemistry and bioorthogonal chemistry\"",
"share": "3"
}
]
},
...
Step4: Ensure Docker service running
Now that we are having our dataset ready, let us ensure docker and docker compose is installed on our system and is running.
sudo systemctl start docker.service
sudo systemctl enable docker.service
sudo systemctl status docker.service
Step5: Ensure Elasticsearch and Kibana service Cluster running
Now let’s start up the elasticsearch cluster using the docker-compose.yml file. You can check out my article on “How to enable audit logging in Elasticsearch” were in we have setup the elasticsearch cluster using docker-compose file.
docker-compose ps
docker-compose up -d
Output:
Name Command State Ports
----------------------------------------------------------------------------------------------------------------------------
elastic-kibana_es01_1 /bin/tini -- /usr/local/bi ... Up (healthy) 0.0.0.0:9200->9200/tcp,:::9200->9200/tcp, 9300/tcp
elastic-kibana_es02_1 /bin/tini -- /usr/local/bi ... Up (healthy) 9200/tcp, 9300/tcp
elastic-kibana_es03_1 /bin/tini -- /usr/local/bi ... Up (healthy) 9200/tcp, 9300/tcp
elastic-kibana_kibana_1 /bin/tini -- /usr/local/bi ... Up (healthy) 0.0.0.0:5601->5601/tcp,:::5601->5601/tcp
elastic-kibana_setup_1 /bin/tini -- /usr/local/bi ... Exit 0
Copy the ca certificate from any elasticsearch docker container as shown below. This is required for us to connect to the elasticsearch cluster and send REST API requests in a secure channel.
docker cp elastic-kibana_es01_1:/usr/share/elasticsearch/config/certs/ca/ca.crt .
Step6: Index Document
Now that we have our elasticsearch cluster up and running. Let’s look at the below python script which we will use to extract the json documents from the prize.json dataset and send it using a POST REST API request to elasticsearch search for indexing.
File: indexDocuments.py
import json
import requests
import sys
indexname = sys.argv[1]
print(indexname)
url = "https://localhost:9200/{}/_doc".format(indexname)
cafile = 'ca.crt'
headers = {'Content-type': 'application/json', 'Accept': 'text/plain'}
username = "elastic"
password = "admin@1234"
# Opening JSON file
f = open('prize.json')
# returns JSON object as
# a dictionary
data = json.load(f)
# print json data
#print(data['prizes'][0])
# print number of documents in the json
count = len(data['prizes'])
print(count)
# index each document
for each in range(count):
print(each)
prizedoc = data['prizes'][each]
r = requests.post(url, data=json.dumps(prizedoc), auth=(username, password), headers=headers, verify=cafile)
print(r.status_code)
# Closing file
f.close()
python indexDocuments.py prizes
Step7: Validate the Index
Once our indexing is done we can navigate to Stack Management – Data View and Create our Data View based on the index source that got generated. Here as you can see there is a prizes index created with each document indexed within that index. But if we closely look at the document field types, every field is of type text. But from our initial inspection of json dataset using jq tool we saw that some of the field values are with numeric data.
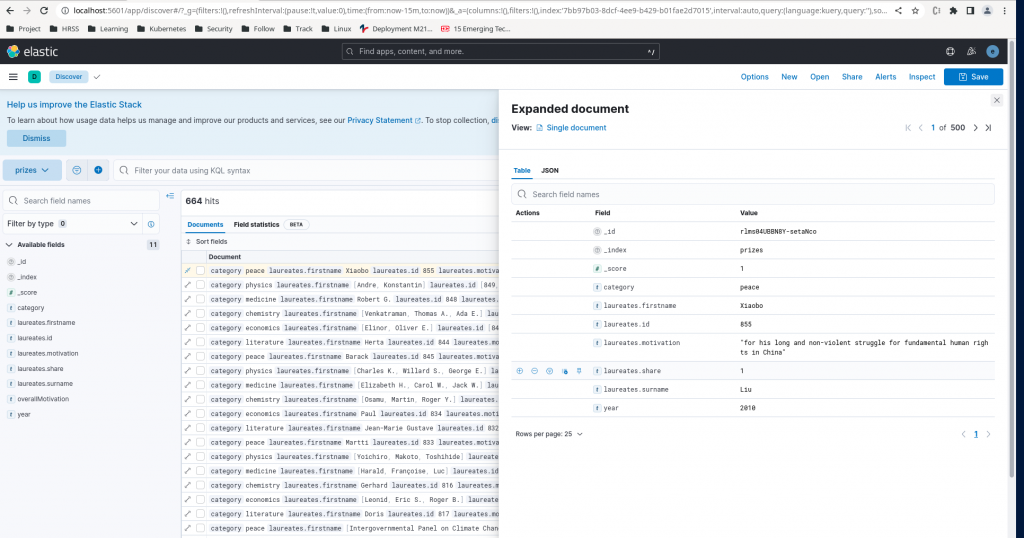
These fields can be mapped to their respective types so we have the correct mapping of the data. Let us see what options we have to map these field types correctly in the document in our next article.
Hope you enjoyed reading this article. Thank you..
Leave a Reply
You must be logged in to post a comment.