Introduction to Git Version Controlling System

Test Environment
Fedora 36 server
Why we need Version Controlling System
We need Version Controlling, in order to keep track of changes to files or a set of files with minimal effort. We will talk about Version Controlling from a System Administrator and a Developer perspective.
System Administrators usually work with scripts and configuration files. In order to keep track of changes to script and configuration files usually System Administrators name files in such a way that they use relevant files for a specific case. This is one way of versioning the files by following some kind of naming convention.
eg.
setup.sh.http - Initial File
config.http - Initial Config File
setup.sh.auth - Initial File with Auth Feature
config.auth - Initial Config File with Auth Feature
setup.sh.https - Initial File with Auth and Security Feature
config.https - Initial Config with Auth and Security Feature
As you can see from the above example the Initial Files have been modified overtime by introducing new features and in order to keep track of changes to these files there was some kind of naming convention followed to identify the files with specific features.
Developers usually work with source code files, configuration files and other dependent files. In order to keep track of changes to these files usually Developers provide some kind of version number to identify their changes.
eg.
v1
helloapp.java - Initial File
helloapp.config - Initial Config File
v2
helloapp.java - Initial File
helloapp.config - Initial Config File
helloapptest1.java - New test1 File
helloapptest2.java - New test2 File
helloapptest1.config - New test1 Config File
helloapptest2.config - New test2 Config File
v3
helloappsecure.java - Updated Initial File with Security Feature
helloappsecure.config - Updated Initial Config File with Security Feature
helloappsecuretest1.java - Updated test1 File with Security Feature
helloappsecuretest2.java - Updated test2 File with Security Feature
helloappsecuretest1.config - Updated test1 Config File with Security Feature
helloappsecuretest2.config - Updated test2 Config File with Security Feature
But this whole process of versioning by following some kind of naming convention or keeping a set of files in a particular version numbered folder may become cumbersome overtime as the number of files that we want to manage increase. We will need some kind of a system that will help in keeping track or recording these changes and maintain it in a database for querying or backup and restoration purpose.
Version Control Benefits
- To keep track of the changes to the files or a set of files with minimal effort
- To revert or restore to a previous version
- Identify what changes were made and who made changes (ie. Auditing)
This is where the Version Controlling System come into picture.
What is Version Controlling
Version Controlling is a way of keeping track or recording changes to files or a set of files which later can be queried. Version Controlling System also help in keeping the files safe with all the changes recorded which later can be restored if required. It helps in identifying what changes went into the file or set of files overtime and who made those changes for audit or tracking purpose.
What are different Version Controlling Tools
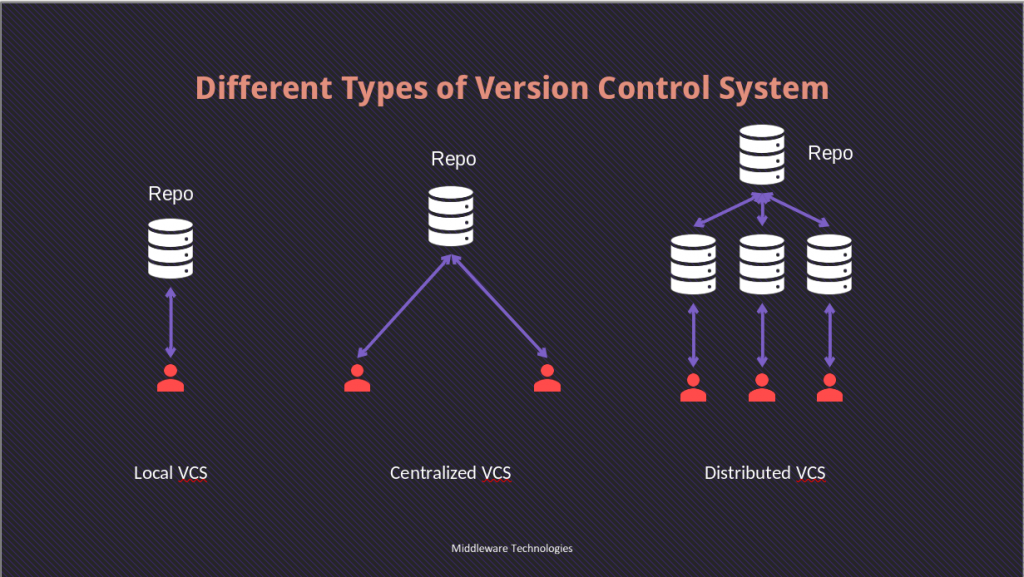
Local Version Control Systems
This was a very basic version control system which was implemented locally on the system to keep track of the files. One such tool is RCS (Revision Control System) which use to keep a set of patch files to keep the file changes and these patch sets are used to re-create the whole file. The main disadvantage of Local Version Control System was there was no way people could collaborate on these files for developments or updates and there was no way to distribute these files to others.
Centralised Version Control Systems
This Version Control System helps in solving the problem of Collaboration to some extent by placing the Version Control System in a Centralized place from where other members could retrieve the files and work on the changes. This system provided another advantage of access control to project files with which only members who are granted permission to a particular set of project or files are able to view or update those files. The only major disadvantage of this system was as it was centralized, if any fatal issue caused the disk to damage the complete versioned database would be at loss (ie. single point of failure). An Example of tool that implement this system is CVS.
Distributed Version Control Systems
This Version Control System mitigates the problem of single point of failure of Version Control Database in CVS and RCS by making a complete checkout of the Versioned database on each and every user system who are collaborating on the project files. This system also provides branching feature in which each member can work on new features or enhancements on separate branch from the main branch without any conflict. This is one of great feature which helped in making the Open Source project collaboration a great success. Many developers around the world can contribute to project by placing their changes in a separate branch from the main branch and can submit their changes for review. These branch changes once reviewed by the Project maintainer could then later be merged into main branch to apply the changes. Some of the popular tools implementing this Distributed Version Control System are Git, BitBucket, Mercurial. Distributed Version Control Systems also allows to set up several types of workflows that aren’t possible in centralized systems, such as hierarchical models.
How Git came into existence and became popular
Linux Kernel one of popular open source project was maintained by passing patch files in archive format. Later they adopted a proprietary Distributed Version Control System named BitKeeper. But later the free usage of the BitKeeper was removed. This change made Linus Torvalds to come up with their own Distributed Version Control System named Git keeping in mind the below.
- Speed
- Simple design
- Strong support for non-linear development (thousands of parallel branches)
- Fully distributed
- Able to handle large projects like the Linux kernel efficiently (speed and data size)
Git is now very popular easy to use and blazing fast with an incredible branching system for non linear development.
Most of the Version Control Systems store changes to files or set of files as delta changes. But Git thinks differently. It thinks of its data as a series of snapshots of a miniature file system. It takes a snapshot of all the files at a point in time. This snapshot contains any files that changes and references to files that haven’t changes at that moment.
As Git clone the complete history of the project, every operation that we carry out with the repository with instantaneous as its locally available. There is no need for the Version Control System to be online as in case of CVS for the operations to be carried out.
Everything in Git is check summed (ie. SHA1 hash 40 character long) before it is stored and is then referred to by that checksum. This means it’s impossible to change the contents of any file or directory without Git knowing about it. Git stores everything in its database not by file name but by the hash value of its contents.
As long as we commit our changes and push them to a distributed repository our changes are safe and there is no danger of losing our data.
How to install and use Version Controlling Tool
For installing Git on an RPM based System you can do the following.
sudo dnf install git-all
Before we start using Git, We need to set some configuration which can be done either at the system wide, globally for a specific user or locally for a specific project. This configuration is done using the below.
git config --global user.name "alice"
git config --global user.email alice@example.com
We can also list all the configuration with their origin as shown below.
git config --list --show-origin
To set main as the default branch name we can do below.
git config --global init.defaultBranch main
Hope you enjoyed reading this article. Thank you..
Leave a Reply
You must be logged in to post a comment.